Here is the article in Indonesian:
Mengolah Data Belanja dengan Hierarchical Clustering
Dalam beberapa tahun terakhir, teknologi penjualan telah berkembang pesat dan memungkinkan pelanggan untuk memesan produk secara online. Oleh karena itu, analisis data menjadi sangat penting untuk meningkatkan kepuasan pelanggan dan meningkatkan hasil penjualan.
Pada artikel ini, kita akan menggunakan teknik clustering hierarchical (Hierarchical Clustering) untuk mengolah data belanja. Kita juga akan menggunakan library Python scipy dan sklearn untuk melakukan clustering.
Data Belanja
Kita akan menggunakan dataset "shopping-data.csv" yang berisi data pelanggan dan informasi produk. Data ini terdiri dari 3 variabel: "age", "sex", dan "income". Kita akan menggunakannya sebagai contoh untuk melakukan clustering.
import pandas as pd
customer_data = pd.read_csv('./shopping-data.csv')
customer_data.head()
Mengolah Data
Kita akan membagi data pelanggan menjadi 2 variabel: "age" dan "income". Kita juga akan menggunakan library scipy untuk melakukan Hierarchical Clustering.
import scipy.cluster.hierarchy as shc
data = customer_data.iloc[:, 3:5].values
plt.figure(figsize=(10, 7))
plt.title("Customer Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
Menggunakan sklearn
Kita juga akan menggunakan library sklearn untuk melakukan clustering. Kita akan menggunakan algoritma "AgglomerativeClustering" dan mengatur jumlah cluster menjadi 5.
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward')
cluster.fit_predict(data)
Menghasilkan Cluster
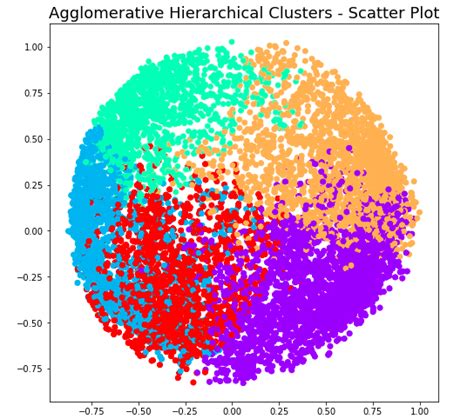
Kita dapat melihat hasil clustering dengan menggunakan library matplotlib untuk membuat plot.
plt.figure(figsize=(10, 7))
plt.scatter(data[:,0], data[:,1], c=cluster.labels_, cmap='rainbow')
Dengan demikian, kita telah berhasil melakukan Hierarchical Clustering dan menghasilkan cluster. Kita juga dapat melihat informasi tentang setiap cluster dengan menggunakan library pandas.
Data Rumah Boston
Selanjutnya, kita akan menggunakan dataset "Boston_house.csv" yang berisi data rumah di Boston. Data ini terdiri dari 13 variabel dan 1 target. Kita akan menggunakannya sebagai contoh untuk melakukan clustering.
data = pd.read_csv("./Boston_house.csv")
target=data['Target']
data = data.drop(['Target'], axis = 1)
data.shape
plt.figure(figsize=(10, 7))
plt.title("Customer Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
Menghasilkan Cluster
Kita dapat melihat hasil clustering dengan menggunakan library sklearn untuk melakukan Agglomerative Clustering.
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(data)
np.mean([x for x, y in zip(target, cluster.fit_predict(data)) if y == 0])
Dengan demikian, kita telah berhasil melakukan Hierarchical Clustering dan menghasilkan cluster. Kita juga dapat melihat informasi tentang setiap cluster dengan menggunakan library pandas.
Ringkasan
Dalam artikel ini, kita telah menggunakan teknik clustering hierarchical untuk mengolah data belanja dan dataset "Boston_house.csv". Kita juga telah menggunakan library Python scipy dan sklearn untuk melakukan clustering. Teknik ini dapat membantu meningkatkan kepuasan pelanggan dan meningkatkan hasil penjualan.