Dalam artikel ini, kita akan melihat bagaimana kita dapat memplot cluster K-Means. K-Means Clustering adalah metode clustering iteratif yang mengsegment data menjadi k cluster, di mana setiap observasi berbelitu kepada cluster dengan mean terdekat (sentroid cluster).
Langkah-Langkah Plotting K-Means Clusters
Artikel ini menunjukkan bagaimana kita dapat visualisasi cluster. Kami akan menggunakan dataset digit untuk tujuan kami.
- Mempersiapkan Data untuk Plotting
Terlebih dahulu, mari kita siapkan data kita.
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
# Load Data
data = load_digits().data
pca = PCA(2)
# Transform the data
df = pca.fit_transform(data)
Dataset digit berisi gambar ukuran 8×8 pixels, yang ditempatkan ke dalam vektor fitur panjang 64. Kami menggunakan PCA untuk mengurangi jumlah dimensi sehingga kita dapat visualisasi hasilnya menggunakan scatter plot 2D.
- Mengaplikasikan K-Means pada Data
Sekarang, mari kita aplikasikan K-Means ke data kita untuk membuat cluster. Di dataset digit ini, kami sudah tahu bahwa label range dari 0 hingga 9, sehingga kami memiliki 10 kelas (atau cluster). Namun, dalam tantangan nyata, ketika melakukan K-Means, tugas paling berat adalah menentukan jumlah cluster.
from sklearn.cluster import KMeans
# Initialize the class object
kmeans = KMeans(n_clusters=10)
# predict the labels of clusters.
label = kmeans.fit_predict(df)
print(label)
Methode fit_predict kmeans mengembalikan array label cluster, di mana setiap data point berbelitu kepada cluster.
- Plotting Label 0 K-Means Clusters
Sekarang, mari kita memahami bagaimana kita dapat memplot individual cluster. Array label mempertahankan indeks atau urutan data points, sehingga kami dapat menggunakan karakteristik ini untuk mengfilter data points menggunakan indexing Boolean dengan numpy.
import matplotlib.pyplot as plt
# filter rows of original data
filtered_label0 = df[label == 0]
# plotting the results
plt.scatter(filtered_label0[:,0] , filtered_label0[:,1])
plt.show()
Kode di atas pertama-tama mengfilter dan mempertahankan data points yang berbelitu kepada cluster label 0, kemudian membuat scatter plot. Lihat bagaimana kami menggunaan Boolean series untuk mengfilter [label == 0]. Indexed the filtered data and passed to plt.scatter as (x,y) to plot.
- Plotting Additional K-Means Clusters
Sekarang, mari kita memplot cluster dengan label 2 dan 8.
# filter rows of original data
filtered_label2 = df[label == 2]
filtered_label8 = df[label == 8]
# Plotting the results
plt.scatter(filtered_label2[:,0] , filtered_label2[:,1] , color = 'red')
plt.scatter(filtered_label8[:,0] , filtered_label8[:,1] , color = 'black')
plt.show()
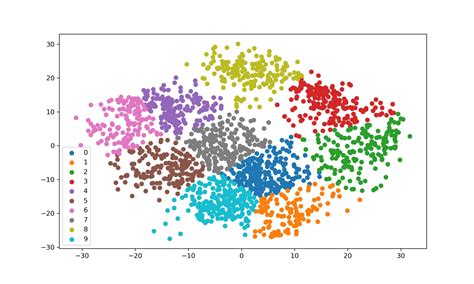
- Plot All K-Means Clusters
Sekarang, mari kita aplikasikan ini ke semua cluster.
# Getting unique labels
u_labels = np.unique(label)
# plotting the results:
for i in u_labels:
plt.scatter(df[label == i , 0] , df[label == i , 1] , label = i)
plt.legend()
plt.show()
- Kesimpulan
Dalam artikel ini, kita melihat bagaimana kita dapat memvisualisasi cluster yang terbentuk oleh algoritma K-Means. Sampai jumpa berikutnya, Selamat Belajar!