이 글에서는, 데이터 분포를 시각화하는 데 겹치는 문제점을 해결하는 다양한 방법을紹介합니다. 특히, 이 문제가 발생하는 이유는 데이터의 밀도가 높은 경우에 주로 겹쳐있기 때문입니다.
1. Jitter 추가: 무작위적인 노이즈 추가
가장 간단한 방법은 Jitter를 추가하는 것입니다. Jitter는 무작위적인 노이즈를 데이터에 추가하여 겹치는 점들을 말 그대로 흔들어 (Jitter)버리는 것입니다. 이렇게 하면, 겹쳐있던 점들이 분산되어 표현되므로, 중간 부분의 밀도가 높다는 것을 알 수 있습니다.

2. 빈도 표현: 데이터의 빈도를 점의 크기로 표현
한편으로는, 데이터의 빈도를 점의 크기로 표현하는 방법을 사용할 수도 있습니다. 이렇게 하면, 겹치는 점들이 분산되어 표현되므로, 중간 부분의 밀도가 낮아진다는 것을 알 수 있습니다.

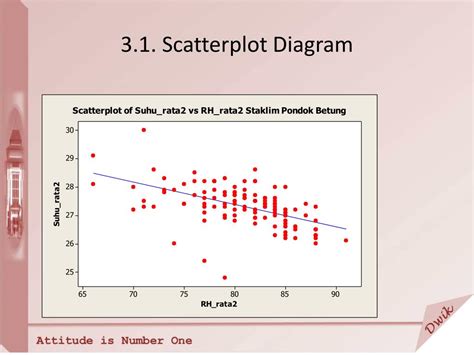
3. 히스토그램과 Scatter Plot 결합: 선형회귀선 추가
하지만, 이 방법들은 각 변수의 분포를 쉽게 파악하기는 어렵습니다. 또한, 변수 간에 정확하게 어떤 관계를 형성하는지 역시 한눈에 확인하기 어렵습니다.
이 경우 히스토그램과 Scatter Plot을 결합하고, 선형회귀선을 추가하여 시각화하는 방법을 사용할 수 있습니다. 모서리 부분에 각 변수의 히스토그램을 추가하여 분포를 한눈에 표시하고, 선형회귀선을 추가하여 독자가 쉽게 두 변수가 양의 직선형 상관관계 (Z = aX+b)를 갖는다는 것을 확인할 수 있습니다.

마지막으로
이 글에서는, 데이터 분포를 시각화하는 데 겹치는 문제점을 해결하는 다양한 방법을紹介했습니다. 각 방법들은 이 próp의 강점과 약점을 가질 수 있으므로, 상황에 따라 적절한 방법을 선택하여야 합니다.
이 글은 제 경험과 노하우를 토대로 쌓아온 결과물입니다. 다음 글에서는, 데이터 시각화 시 유의해야 할 점 특히 선, 색 등을 고를 때 유의해야 할 점들을 다뤄보도록 하겠습니다.