Saya pernah mengalami masalah dengan sintesis IM (Instruction Memory) yang dibahas dalam pertanyaan sebelumnya (Bagaimana membuat memori instruksi yang dapat disynthesiskan dalam SystemVerilog?). Setelah meretas kode sebagai nasihat (ff dengan statement case), masalah lain muncul.
Masalah:
Instruksi CPU memiliki delay satu siklus dari Program Counter. Karena itu, ketika instruksi cabang (nomor i) datang, Program Counter sudah menjadi (i+1) dan kemudian datang instruksi (i+1) dan PC adalah PC_branch. Bagaimana cara memperbaiki ini? Delay disebabkan oleh ff dalam IM.
Kode dan waveform seperti dibawah:
Kode:
always_ff @(posedge clk) begin
case (addr)
32'd0 : rom_ff <= 32'h2408000F; // a = F
32'd1 : rom_ff <= 32'h240A0000; // res = 0
32'd2 : rom_ff <= 32'h01485021; // (*) res = res + a
32'd3 : rom_ff <= 32'h2508FFFF; // a = a - 1
32'd4 : rom_ff <= 32'h1500FFFD; // if (a != 0) goto (*)
32'd5 : rom_ff <= 32'hAC0A0ADD;
default : rom_ff <= 32'h0;
endcase
end
Waveform CPU signal:
…
Dalam kode di atas, saya menemukan masalah yang terkait dengan pipelining instruksi. Saya asumsikan bahwa Anda akan menyintesis prosesor Anda untuk menjalankannya pada FPGA pada titik tertentu, sehingga menghapus register antara memori instruksi dan bagian lain dari CPU tidak menjadi pilihan.
Untuk memperbaiki masalah ini, saya memiliki tiga opsi.
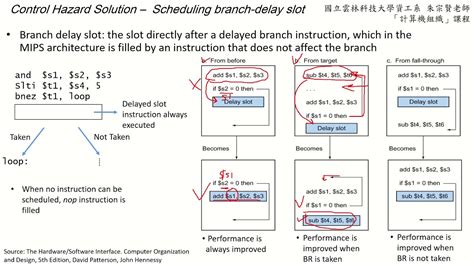
Lupakan masalah. Setelah semua, prosesor Anda masih berperilaku secara deterministik – hanya masalah bahwa ia akan menjalankan instruksi tambahan setelah cabang. Instruksi yang datang kemudian sebagai jika instruksi sebelumnya tidak pernah ada. Banyak processor memiliki delay slot seperti ini dan compiler dapat menghandlenya dengan baik.
Stall pipeline secara unconditional setelah cabang diambil. Artinya, Anda akan menghentikan Program Counter untuk satu siklus dan menginsersi NOP ke dalam pipeline ketika Anda menemukan cabang, yang efektif menghilangkan delay slot.
Menghapus pipeline ketika cabang diambil. Artinya, prosesor Anda akan terus menjalankan instruksi stream normal hingga ia mendeteksi bahwa ia harus loncat. Pada titik ini, ia akan menghapus semua instruksi setelah loncat yang telah diambil.
Anda juga dapat memeriksa bagaimana pipeline RISC classic dikelola dan apa yang disebut hazard dalam pipeline. Ketika Anda menjalankan akses memory pada prosesor Anda, Anda mungkin juga akan menemukan hazards yang disebabkan oleh data yang di-load dari memory tidak tersedia dengan cepat. Anda dapat menghandle masalah ini dengan cara stalling pipeline atau menerima bahwa Anda memiliki delay slot, yang berarti data yang di-load dari memory tidak tersedia segera untuk instruksi yang mengikutinya.
Opisi lainnya:
Saya juga menyarankan menggunakan prediksi cabang. Ada banyak algoritma prediksi cabang yang dapat Anda riset. Banyak processor modern menggunakan prediksi cabang. Jadi, jika prediksi cabang benar, Anda menang dan menyelamatkan siklus. Jika prediksi cabang salah, Anda harus menghapus data.
Eksekusi out-of-order juga dapat digunakan untuk menjaga CPU sibuk. Dalam teknik ini, banyak siklus yang terbuang tidak akan diabaikan. Urutan eksekusi instruksi tidak sesuai dengan urutan asli dalam eksekusi out-of-order.
Bacaan lanjut:
Saylor Academy's free online certificate course on Computer Architecture. It covers MIPS. Lihat: https://learn.saylor.org/course/view.php?id=71
Free online course from Coursera: https://www.coursera.org/learn/comparch/
Kata-kata kunci: pipelining instruksi, memori data, memori instruksi, delay slot, prediksi cabang, eksekusi out-of-order.