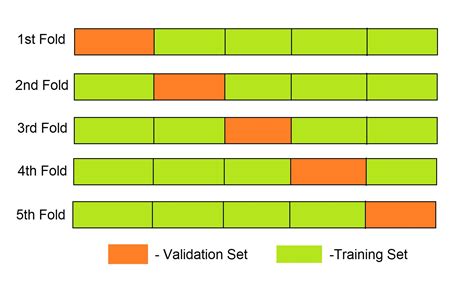
Dalam pengembangan model regresi, penting untuk memastikan bahwa model yang dibuat dapat membantu meningkatkan kinerja prediksi dan mengurangi masalah overfitting dan underfitting. Salah satu cara untuk mencapai tujuan ini adalah dengan menggunakan K-Fold Cross Validation.
Dalam penelitian ini, kami menggunakan Sklearn untuk mengembangkan tiga model regresi yang berbeda (Linear, Decision Tree, dan Random Forest) dan mengevaluasi kinerja prediksi masing-masing menggunakan cross-validation. Kami menggunakan metode neg_mean_squared_error sebagai metric evaluasi dan K-fold sebagai prosedur cross-validation.
Hasil penelitian menunjukkan bahwa model decision tree memiliki mean prediction error sebesar $72002, sedangkan model linear regression memiliki score sebesar $72933. Model Random Forest Regressor terlihat sebagai model yang sangat berpotensi dengan error prediksi sebesar $49642.
Dalam bagian ini, kami juga membahas kelebihan dan kelemahan K-Fold Cross Validation. Kelebihan-kelebihannya antara lain dapat mengurangi overfitting dan underfitting, dapat menangani data yang tidak seimbang, serta dapat digunakan untuk tuning parameter model.
Selain itu, kami juga membahas variasi-variasi K-Fold Cross Validation, seperti Repeated K-Fold, Stratified K-Fold, Group K-Fold, dan StratifiedGroupKFold. Masing-masing memiliki kelebihan dan kelemahan sendiri, dan harus dipertimbangkan dalam pengembangan model.
Dalam kesimpulan, kami menyarankan menggunakan K-Fold Cross Validation dalam pengembangan model regresi untuk meningkatkan kinerja prediksi dan mengurangi masalah overfitting dan underfitting. Dengan demikian, kita dapat memilih model yang paling berpotensi dan meningkatkan kinerja prediksi.
Frequently Asked Questions (FAQs)
Q. Apa arti K dalam K-Fold Cross Validation?
K mewakili jumlah lipatan, atau bagian, yang dibagi dari dataset untuk cross-validation. Berdasarkan nilai K, dataset terbagi dan menciptakan k jumlah lipatan. Contohnya, jika k = 10, maka menjadi 10-fold cross-validation.
Q. Apakah ada aturan formal untuk memilih nilai K?
Tidak ada aturan formal, namun biasanya dilakukan k-fold cross-validation menggunakan k = 5 atau k = 10, karena nilainya tidak terlalu tinggi sehingga mengalami bias yang sangat tinggi dan variabilitas yang sangat rendah.
Q. Apa faktor-faktor yang harus dipertimbangkan saat memilih nilai K?
Nilai K dipilih agar data sample (train/test) dapat besar enough untuk mewakili dataset lebih luas. Memilih k = 10 menghasilkan model dengan bia yang rendah dan varianse yang moderat. Memilih k = n (n = ukuran dataset) memastikan bahwa setiap sampel digunakan dalam holdout dataset. Ini disebut leave-one-out cross-validation.
Q. Apa fungsi cross_val_score() method?
Fungsi cross_val_score() mengevaluasi skor dengan cross-validation dan mengembalikan array skor estimator untuk setiap larian cross-validation. Di sini, kita dapat menentukan prosedur cross-validation untuk memvalidasi model (dalam kasus ini, adalah k-fold).