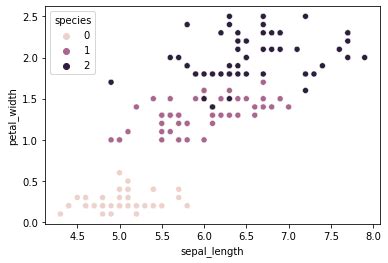
Iris adalah salah satu dataset paling populer di bidang machine learning, dikembangkan oleh Edgar Anderson pada tahun 1936. Dataset ini berisi 150 eksemplar iris yang terbagi menjadi tiga spesies: Setosa, Versicolor, dan Virginica. Tiap eksemplar memiliki enam atribut: panjang sepal, lebar sepal, panjang petal, lebar petal, dan kelas.
Dalam artikel ini, kita akan menggunakan Python dan library Matplotlib untuk melakukan analisis dataset Iris. Kita akan melihat distribusi data sepal length dan sepal width untuk tiap spesies iris, serta membuat diagram scatter untuk memvisualkan hubungan antara dua variabel tersebut.
Membaca Data
Pertama, kita perlu membaca data Iris menggunakan Pandas:
import pandas as pd
import matplotlib.pyplot as plt
iris = pd.read_csv('iris.csv')
Membagi Data Menurut Kelas
Kita ingin melihat distribusi data sepal length dan sepal width untuk tiap spesies iris. Karena itu, kita akan membagi data menurut kelas:
setosa = iris[iris['class'] =='setosa']
versicolor = iris[iris['class'] =='versicolor']
virginica = iris[iris['class'] =='virginica']
Membuat Diagram Scatter
Kita akan membuat diagram scatter untuk memvisualkan hubungan antara sepal length dan sepal width untuk tiap spesies:
setosa_sc = plt.scatter(setosa['sepal length'], setosa['sepal width'], marker='o', color='b')
versicolor_sc = plt.scatter(versicolor['sepal length'], versicolor['sepal width'], marker='x', color='g')
virginica_sc = plt.scatter(virginica['sepal length'], virginica['sepal width'], marker='v', color='k')
plt.legend((setosa_sc, versicolor_sc, virginica_sc), ('setosa', 'versicolor', 'virginica'), loc='upper left')
Menambahkan Legend
Kita akan menambahkan legend untuk memvisualkan informasi tentang tiap spesies:
plt.xlabel("Sepal Length")
plt.ylabel("Sepal Width")
plt.title("Iris Dataset", fontsize=20)
plt.grid(True)
plt.show()
Mengatur Gaya Diagram
Kita dapat mengatur gaya diagram dengan menggunakan library Matplotlib. Kita akan menggunakan style "ggplot" untuk membuat diagram terlihat lebih menarik:
plt.style.use('ggplot')
Membuat Diagram Scatter (Lagi!)
Karena kita sudah mengatur gaya diagram, kita dapat membuat diagram scatter lagi:
setosa = iris[iris['class'] =='setosa']
versicolor = iris[iris['class'] =='versicolor']
virginica = iris[iris['class'] =='virginica']
setosa_sc = plt.scatter(setosa['sepal length'], setosa['sepal width'], marker='o', color='b')
versicolor_sc = plt.scatter(versicolor['sepal length'], versicolor['sepal width'], marker='x', color='g')
virginica_sc = plt.scatter(virginica['sepal length'], virginica['sepal width'], marker='v', color='k')
plt.legend((setosa_sc, versicolor_sc, virginica_sc), ('setosa', 'versicolor', 'virginica'), loc='upper left')
plt.grid(True)
plt.xlabel("Sepal Length")
plt.ylabel("Sepal Width")
plt.title("Iris Dataset", fontsize=20)
Mengatur Ukuran Diagram
Kita dapat mengatur ukuran diagram dengan menggunakan rcParams:
plt.rcParams["figure.figsize"] = (3, 3) # Set size to (3, 3)
Dengan demikian, kita telah melakukan analisis dataset Iris dengan Python dan Matplotlib. Kita dapat melihat distribusi data sepal length dan sepal width untuk tiap spesies iris, serta membuat diagram scatter untuk memvisualkan hubungan antara dua variabel tersebut.