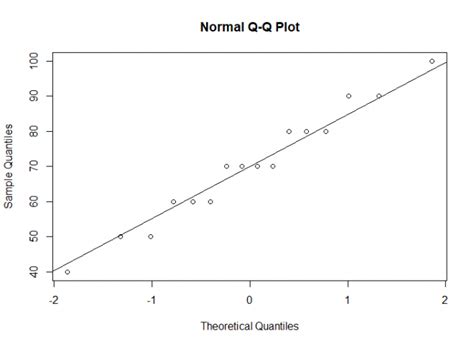
Ketika kita membandingkan dua distribusi, salah satu cara yang paling efektif adalah menggunakan plot-plot atau plot-qq. Kedua metode ini berbasis pada fungsi distribusi kumulatif (CDF), yang dapat membantu kita memahami bagaimana data kami didistribusikan.
Sebagai contoh, mari kita lihat distribusi normal standar. Dalam distribusi ini, sekitar 68% dari data berada di wilayah antara garis merah, sementara sisanya berada di wilayah antara garis biru. Jika kita menggunakan proporsi distribusi yang telah kami lewati untuk mengevaluasi kecocokan antara dua distribusi (yaitu, plot-pp), maka kita akan mendapatkan banyak resolusi di pusat distribusi, tetapi kurang pada ekornya.
Di sisi lain, jika kita menggunakan kuantil untuk mengevaluasi kecocokan antara dua distribusi (yaitu, plot-qq), maka kita akan mendapatkan resolusi yang sangat baik di bagian akhir, tetapi lebih sedikit di bagian tengah. Karena analis data biasanya lebih peduli tentang ekor distribusi, yang akan lebih berpengaruh pada inferensi, maka plot-qq jauh lebih umum daripada plot-pp.
Untuk melihat fakta-fakta ini dalam tindakan, mari kita berjalan melalui konstruksi plot-plot dan plot-qq. Kita dapat menggunakan R sebagai contoh, meskipun tidak perlu.
set.seed(1) # this makes the example exactly reproducible
N = 10 # I will generate 10 data points
x = sort(rnorm(n=N, mean=0, sd=1)) # from a normal distribution w/ mean 0 & SD 1
n.props = pnorm(x, mean(x), sd(x)) # here I calculate the probabilities associated
# w/ these data if they came from a normal
# distribution w/ the same mean & SD
# I calculate the proportion of x we've gone through at each point
props = 1:N / (N+1)
n.quantiles = qnorm(props, mean=mean(x), sd=sd(x)) # this calculates the quantiles (ie
# z-scores) associated w/ the props
my.data = data.frame(x=x, props=props, # here I bundle them together
normal.proportions=n.props,
normal.quantiles=n.quantiles)
round(my.data, digits=3) # & display them w/ 3 decimal places
# x props normal.proportions normal.quantiles
# 1 -0.836 0.091 0.108 -0.910
# 2 -0.820 0.182 0.111 -0.577
# 3 -0.626 0.273 0.166 -0.340
# 4 -0.305 0.364 0.288 -0.140
# 5 0.184 0.455 0.526 0.043
# 6 0.330 0.545 0.600 0.221
# 7 0.487 0.636 0.675 0.404
# 8 0.576 0.727 0.715 0.604
# 9 0.738 0.818 0.781 0.841
# 10 1.595 0.909 0.970 1.174
Saya tidak tahu apakah Anda menggunakan R, tetapi mudah-mudahan itu akan cukup jelas: plot-plot ini tidak terlalu berbeda, karena hanya ada sedikit data dan kami membandingkan normal normal dengan distribusi teoretis yang benar, sehingga tidak ada sesuatu yang istimewa untuk dilihat baik di pusat maupun di ujung distribusi.
Untuk menunjukkan perbedaan-perbedaan ini dengan lebih baik, saya merencanakan distribusi t (tail-tail) dengan 4 derajat kebebasan, dan distribusi bi-modal di bawah ini. Ekor lemak jauh lebih khas dalam plot-qq, sementara bagian tengah lebih khas dalam plot-pp.
Dalam kesimpulan, pemahaman fungsi distribusi kumulatif (CDF) dapat membantu kita memahami bagaimana data kami didistribusikan. Dengan menggunakan plot-plot atau plot-qq, kita dapat mengevaluasi kecocokan antara dua distribusi dan membuat inferensi yang lebih akurat.